

























- How to Build an AI Scheduling Assistant for Healthcare Providers (Step by Step)
- How Can You Fix Hospital Scheduling Failures at Scale With AI?
- Identify High-Impact Scheduling Use Cases and Stakeholders
- Designing an Enterprise AI-Based Hospital Scheduling System (Architecture)
- Data, Models, and Decision Logic Behind AI Scheduling
- Ensuring Reliable and Safe AI Scheduling Decisions
- EHR Integration & Interoperability Strategy
- Designing Patient and Staff Interaction Layers
- Compliance, Privacy & Security
- MLOps & Continuous Monitoring
- Common Implementation Pitfalls and How to Avoid Them
- Cost Model & Procurement Checklist
- Measuring the 35% Operational Efficiency Gain
- Change Management & Clinical Adoption
- Build vs Buy: Strategic Decision Framework
- Future Outlook of AI Scheduling Systems in Healthcare
- Why Choose Appinventiv for Healthcare AI Scheduling Systems
- Frequently Asked Questions
Key takeaways:
- Traditional scheduling fails at scale without predictive and optimization layers.
- AI-driven scheduling improves utilization, reduces no-shows, and stabilizes workforce allocation.
- Enterprise architecture, FHIR integration, and governance determine long-term success.
- Measurable gains require structured validation, monitoring, and disciplined phased rollout.
- Strategic build-versus-buy decisions shape scalability, compliance, and operational ROI.
Your scheduling system is leaking revenue. It may not be obvious, but the signs are already there. An AI scheduling assistant for healthcare becomes critical when over 60% of patients skip appointments due to scheduling hassles, as reported by Business Wire, leaving gaps that quietly drain capacity and increase costs.
If you manage hospital operations across departments or facilities, you see this play out every week. Clinics appear fully booked, yet valuable slots go unused. Teams spend hours calling patients, adjusting schedules, and trying to fill last-minute cancellations.
Overtime rises, but the access and throughput do not improve. It is not a single failure. It is a steady drag on performance.
Most systems struggle because they rely on fixed templates and disconnected tools to manage something that constantly changes.
An AI scheduling assistant for healthcare shifts this from reactive coordination to real-time decision-making. It identifies no-show risks early, fills gaps dynamically, and aligns staff with actual demand.
When done right, this approach can drive up to 35% improvement in operational efficiency while maintaining control and compliance.
Manual scheduling causes idle slots and rising no-shows. Build an AI scheduling assistant that predicts demand and fills capacity automatically.
How to Build an AI Scheduling Assistant for Healthcare Providers (Step by Step)
Building an AI scheduling assistant for healthcare requires more than a model. You are designing a system that reads clinical data, predicts behavior, and writes decisions back into live workflows without breaking them. Each step must hold up under real load, not just in testing.

Step 1: Define One Scheduling Problem With Measurable Impact
You need a tightly scoped problem with clear financial or operational impact, or the system will drift into generic automation.
Start by isolating one use case where scheduling inefficiency is visible in metrics. Look at departments where no-show rates exceed 15 to 25 percent or where slot utilization drops below expected capacity.
Tie the problem to a number. For example, reduce missed appointments in a specialty clinic by a fixed percentage within 90 days.
This clarity drives how you design models, what data you prioritize, and how you measure success. Without it, your AI appointment scheduling for hospitals effort becomes a feature, not an operational system.
Step 2: Audit, Clean, and Structure Scheduling Data
Model accuracy depends on event-level data consistency, not volume.
You need at least 12 to 18 months of structured appointment data. Focus on event sequences, not just final outcomes. Capture booking time, confirmation status, cancellation timing, and no-show labels.
Then standardize:
- Normalize cancellation codes across departments
- Remove duplicate patient identifiers
- Validate timestamp order across events
Build a feature-ready dataset. This includes lead time, prior attendance ratio, and appointment type. If these inputs are inconsistent, your predictive scheduling in hospitals will fail under real conditions.
At this stage, you are not training models. You are defining what the system is allowed to learn.
Step 3: Define Integration Boundaries With the EHR
You must control how data flows in and out before enabling any automation.
Map how your assistant will interact with scheduling systems. Start with read access through FHIR resources such as Appointment, Slot, and Schedule. If you rely on legacy systems, use HL7 feeds and normalize them before use.
Do not enable write-back early.
Define:
- Where recommendations appear for schedulers
- How conflicts are handled
- What validation rules must pass before any update
A stable EHR-integrated scheduling system depends on strict control of write operations. Without this, you risk double bookings and data inconsistencies.
Step 4: Build a Focused Prediction Layer
Start with a calibrated no-show prediction model that performs consistently across segments.
Use structured data models such as gradient boosting. Train on features like booking lead time, prior no-show rate, visit type, and reminder response behavior.
Evaluate beyond accuracy:
- Calibration, so predicted probabilities match real outcomes
- Precision at high-risk thresholds, where decisions are made
This is the core of predictive scheduling in hospitals. If your probabilities are not reliable, any downstream scheduling decision will amplify errors.
Keep the model simple enough to explain. You need to justify predictions during clinical review.
Step 5: Translate Predictions Into Scheduling Decisions
You must convert probabilities into constrained, rule-based actions. Define how the system acts on risk scores.
For example:
- If no-show probability crosses a threshold, allow controlled overbooking
- If a slot is cancelled, trigger waitlist matching within defined rules
- Adjust reminder cadence based on patient behavior
Use constraint-based logic. Factor in provider availability, room limits, and specialty rules. This is where your system becomes an AI-driven healthcare scheduling solution instead of a reporting tool.
You are now making decisions that affect real operations. Guardrails are mandatory.
Step 6: Validate in Read-Only Mode
You need to test decisions against real outcomes before touching live scheduling.
Run the system in parallel with current workflows. Generate recommendations but do not execute them.
Track:
- Prediction accuracy against actual attendance
- Decision alignment with real scheduling outcomes
- Edge cases where the system fails
This phase reveals gaps in both data and logic. Fix them here. Once you move to automation, errors become operational problems.
Step 7: Launch a Controlled Pilot in One Department
You validate adoption and system behavior under real conditions with limited risk.
Deploy in a single department with a controlled scope. Enable partial automation, but keep manual override active at all times.
Monitor:
- Scheduler interaction with recommendations
- Acceptance and override rates
- Impact on slot utilization and wait times
This step determines if your system fits daily workflows. If users bypass it, scaling will fail.
Step 8: Measure Operational Impact With Baseline Comparison
You prove value through operational metrics, not model performance.
Compare pre- and post-deployment metrics:
- No-show rate reduction
- Slot utilization improvement
- Change in scheduling effort
Use the same baseline period for accurate comparison. This is where AI in healthcare operations moves from concept to measurable performance.
If results are inconsistent, refine before scaling.
Step 9: Expand Across Departments With Standardized Controls
You scale only after stabilizing performance and defining repeatable rules. Extend the system across specialties and facilities.
Standardize:
- Data pipelines
- Model retraining cycles
- Scheduling rules and thresholds
Ensure integration can handle increased volume. At this stage, you are building a network-wide AI scheduling system for clinics that supports broader capacity planning.
Step 10: Maintain Model Performance and System Reliability
You sustain performance through continuous monitoring and controlled updates.
- Track model calibration, feature drift, and system usage.
- Retrain models on rolling data windows.
- Capture scheduler feedback and feed it back into model updates.
Define clear triggers for retraining and rollback. This keeps your AI scheduling assistant for healthcare reliable as patient behavior and demand patterns shift.
You start with one controlled use case. You validate data, models, and decisions in stages. Then you expand with discipline.
This is how you move from a basic model to a system that supports daily scheduling decisions across hospital operations without creating risk.
How Can You Fix Hospital Scheduling Failures at Scale With AI?
Hospital scheduling does not break all at once. It slows operations down over time.
You see it in:
- Full calendars but unused capacity
- Rising no-shows and lost revenue
- Staff spending hours on manual coordination
- Disconnected systems across EHR, call centers, and portals
- Reactive workforce planning instead of demand-based allocation
The core issue is simple. Scheduling is being managed as an administrative task when it is actually a prediction-and-optimization problem.
As part of digital transformation in healthcare, many systems are shifting toward intelligent operations, especially as AI improves efficiency across clinical and administrative workflows.
An AI scheduling assistant for healthcare fixes this by acting as a real-time coordination layer.
It enables:
- Smarter booking across chat, voice, and portals, similar to AI chatbots in healthcare
- Predictive scheduling that flags no-show risks early
- Automatic waitlist filling and rescheduling
- Demand-based staffing and workforce alignment
- Balanced patient flow across facilities
This is where AI in healthcare administration becomes practical. Scheduling moves from reactive coordination to continuous optimization of capacity, workforce, and patient access.
Identify High-Impact Scheduling Use Cases and Stakeholders
AI scheduling delivers value only when tied to clearly defined operational use cases and accountable stakeholders.
This focus aligns with broader industry investment trends, where AI-driven companies now account for over 40% of global digital health funding.
Before building anything, hospitals should identify which scheduling problems matter most and who is responsible for outcomes. Not all use cases carry equal financial or clinical impact.
Below is a practical mapping framework:
| Use Case | Primary Stakeholders | Operational Objective |
|---|---|---|
| After-hours appointment booking | Patients, call center leads | Increase access without expanding staff hours |
| Waitlist auto-fill management | Schedulers, specialty admins | Reduce idle capacity and revenue leakage |
| No-show risk mitigation | Ops leaders, finance | Protect high-value specialty time |
| Post-discharge follow-up scheduling | Care coordinators | Reduce readmission risk |
| Mental health triage routing | Clinicians, intake teams | Match urgency with the correct provider |
A simple stakeholder map should include:
- Clinical leadership
- Operations management
- IT integration owners
- Compliance officers
- Patient access teams
This prevents departmental optimization from becoming system-level misalignment.
Also Read: ERP in Healthcare
Designing an Enterprise AI-Based Hospital Scheduling System (Architecture)
An enterprise AI-based hospital scheduling system only works when prediction, optimization, and EHR integration are constructed as separate but tightly coordinated layers.
The broader AI in healthcare market is expanding at nearly 37% annually and is projected to grow into a $600+ billion industry, making infrastructure-grade architecture a strategic requirement rather than an experimental choice.
In large health systems, architectural mistakes show up quickly. A model performs well in testing but fails once real appointment traffic hits it. An integration writes back incorrectly and creates duplicate bookings. Or latency spikes during peak hours,s and schedulers lose trust. The design has to anticipate these realities from day one.
High-Level Architecture Layers
Each layer should solve one operational problem clearly and independently.
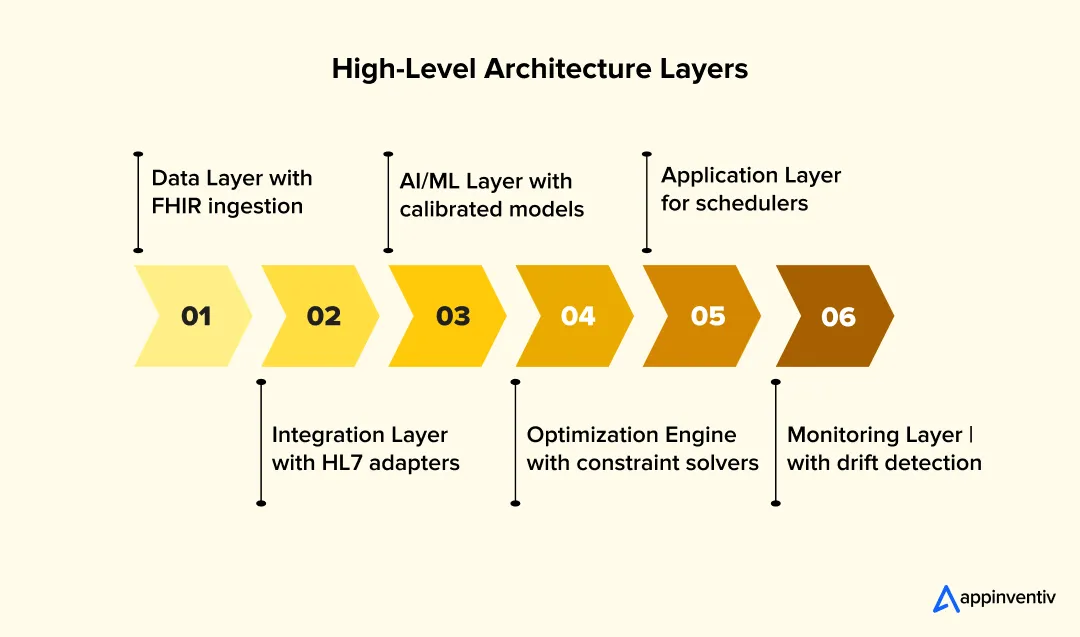
Data Layer
This layer defines what the system can learn and how reliably it can act.
At a minimum, your pipeline should ingest:
- FHIR R4 resources such as Appointment, Slot, Schedule, Patient, Practitioner, and Location
- Historical appointment state changes, including booking time, confirmation status, cancellation timing, and no-show outcome
- Shift and staffing rosters with skill tags and departmental mappings
- Payer class and visit type data for revenue-weighted optimization
- Optional signals like public holidays or severe weather in high-density regions
In enterprise deployments, HL7 SIU and ADT messages are often streamed into Kafka, normalized into FHIR-compatible formats, and stored in a governed analytics warehouse. Before features are generated, automated checks should validate timestamps, remove duplicate patient identifiers, and flag incomplete records. Without this, model performance will quietly degrade.
Integration Layer
This layer ensures the system can safely read from and write back to the EHR without disrupting clinical workflows.
Core elements include:
- HL7 v2 parsers for legacy scheduling feeds
- FHIR REST APIs for modern bidirectional updates
- An API gateway enforcing OAuth2 authentication, request throttling, and full audit logging is essential. APIs in healthcare play a foundational role in securely connecting scheduling systems.
- Event streaming via Kafka or RabbitMQ so cancellations and slot changes propagate in near real time
To prevent double-booking in high-volume clinics, implement optimistic locking and idempotency tokens on appointment updates. Write-back operations should include validation checkpoints so that failed transactions automatically roll back.
AI / ML Layer
This layer converts structured appointment history into calibrated risk scores.
A production setup should include:
- A feature store, such as Feas, maintains consistent definitions for variables like lead time, prior no-show ratio, and reminder engagement
- Automated retraining workflows orchestrated with Airflow or Argo
- A model registry like MLflow to track versions and approval states
- Explainability tooling using SHAP to display per-prediction feature impact
For no-show prediction, gradient boosting models such as XGBoost or LightGBM are typically effective, consistent with how machine learning in healthcare is applied to structured clinical data. Performance evaluation should focus not only on AUC but also on calibration curves and Brier scores, because overbooking strategies rely on accurate probability estimates.
Optimization Engine
This layer translates risk predictions into scheduling decisions under real-world constraints.
Key components include:
- Constraint solvers such as Google OR-Tools CP-SAT to handle provider availability, room limits, and specialty restrictions
- Stochastic overbooking models that calculate expected attendance using predicted probabilities
- Demand-to-staff matching algorithms aligning forecasted patient load with skill-based rosters
Clinical governance rules must be encoded directly into optimization logic. For example, certain specialties may cap overbooking at predefined limits to protect patient safety.
Application Layer
This is the operational surface where schedulers and administrators interact with the system.
It should provide:
- Dashboards showing predicted versus actual attendance, specialty-level utilization, and overtime variance
- A scheduler console with override capability and transparent reasoning behind recommendations
- Secure patient self-service channels synchronized with the central scheduling engine
Every override should be logged. Those logs later feed back into model refinement and audit reporting.
Monitoring Layer
This layer protects system reliability and business performance over time.
Enterprise monitoring should track:
- Feature distribution drift compared to training baselines
- Prediction accuracy decay across specialties
- Operational KPIs such as slot fill rate, revenue per appointment hour, and average wait time
- API latency and uptime thresholds, especially during peak morning loads
Monitoring data should integrate with centralized observability tools, supporting the kind of business intelligence in healthcare reporting that operations leaders already rely on.
Recommended Technology Stack
Technology choices should reflect stability, interoperability, and explainability requirements in regulated healthcare environments.
- HAPI FHIR or managed FHIR services
Provides standards-based interoperability and simplifies deployment of an EHR-integrated scheduling system. - XGBoost or LightGBM
Reliable performance for structured no-show prediction tasks common in hospital datasets. - PyTorch or TensorFlow
Useful for advanced modeling, such as sequence-based cancellation forecasting or reinforcement learning allocation experiments. - SHAP
Enables transparent explanation of predictions for compliance reviews and clinician validation. - Kubernetes
Supports horizontal scaling of inference services across facilities, a natural fit with cloud computing in healthcare infrastructure strategies. - Airflow or Argo Workflows
Automates retraining, validation, and controlled deployment within a governed MLOps pipeline.
When these layers are implemented deliberately, Artificial intelligence scheduling assistant development becomes an infrastructure decision, not just a modeling exercise. The architecture is what ultimately determines whether the AI scheduling system for clinics delivers sustained hospital capacity optimization or becomes another disconnected tool.
Data, Models, and Decision Logic Behind AI Scheduling
Accurate scheduling depends on clean data, reliable models, and clear decision rules. If any one of these fails, the system will produce unstable results. Strong systems start with data discipline, then move to prediction, and finally to decision-making.
Build a Reliable Data Foundation
Model performance depends on structured, consistent data across the full appointment lifecycle.
You need complete visibility into how appointments behave over time.
Core datasets:
| Data Type | What It Captures |
|---|---|
| Appointment history | Booking time, status changes, outcomes |
| No-show & cancellations | Consistent labels across departments |
| Appointment metadata | Specialty, duration, revenue weight |
| Provider schedules | Shifts, availability, constraints |
| Patient behavior | Attendance patterns, response timing |
| Reminder engagement | SMS clicks, confirmations, reschedules |
Key actions:
- Standardize cancellation definitions
- Remove duplicate records
- Validate timestamps and event order
Clean data is the starting point for predictive analytics in healthcare and enables accurate forecasting across scheduling workflows. It also lays the groundwork for broader automation in healthcare operations.
Engineer Features That Reflect Real Behavior
Features must capture patterns that affect attendance, not just basic attributes.
High-impact features:
- Lead time between booking and visit
- Prior no-show ratio (rolling windows)
- Appointment type weighting
- Day-of-week and seasonal patterns
- Distance or travel proxy
- Patient behavior clusters
Example: A patient booking 30 days in advance with past reschedules behaves differently from a same-week booking
These distinctions improve workforce planning and drive more accurate scheduling decisions.
Select and Validate Prediction Models
Start simple, then improve only if data supports it.
Model progression:
| Stage | Model Type | Purpose |
|---|---|---|
| Baseline | Logistic regression | Transparency and quick validation |
| Advanced | XGBoost / LightGBM | Capture nonlinear behavior |
| Extended | Deep models | Sequence-based patterns |
Evaluation must go beyond accuracy:
- Calibration (probability reliability)
- Precision at high-risk thresholds
- Brier score for prediction quality
This is where predictive analytics in healthcare directly impacts scheduling outcomes. Poor calibration will lead to bad decisions, even if accuracy looks high.
Add Optimization and Decision Logic
Predictions must translate into constrained, real-world scheduling actions.
You need systems that act, not just predict.
Core decision layers:
| Layer | Function |
|---|---|
| Overbooking logic | Fill high-risk slots safely |
| Waitlist matching | Replace cancellations in real time |
| Capacity allocation | Distribute load across facilities |
| Staff alignment | Match demand with workforce |
Use constraint-based models:
- Provider availability
- Room limits
- Specialty rules
For more advanced setups:
- CP-SAT solvers for multi-site optimization
- Reinforcement learning for adaptive scheduling
This moves the system into prescriptive analytics in healthcare, where decisions are optimized based on predicted outcomes.
Add Conversational and Interaction Layer
The system must interact with patients and staff in real time.
This layer ensures adoption.
Core components:
- Intent classification (booking, cancel, reschedule)
- Dialogue logic tied to real availability
- Escalation to human schedulers when needed
This is where conversational AI in healthcare connects the system to actual users across chat, voice, and portals.
Maintain Human Oversight and Governance
Human validation is required for trust and long-term reliability.
Control mechanisms:
- Scheduler override workflows
- Explainability dashboards for predictions
- Clinical review during pilot phases
Track:
- Override frequency
- Decision acceptance rates
- Model drift over time
Each override becomes training data for improvement.
Ensuring Reliable and Safe AI Scheduling Decisions
AI scheduling systems must produce decisions that are accurate, traceable, and safe to execute. If the system guesses or sends incomplete data, it will create booking errors and compliance risks. These are common AI challenges in healthcare, especially during real-world deployment.
Ground Decisions in Real-Time Data
Every recommendation must be based on live, verified data, not model assumptions.
| Input Source | Purpose |
|---|---|
| FHIR Slot & Schedule | Validate real availability |
| Provider calendars | Confirm working hours |
| Hospital policies | Enforce booking rules |
| Insurance data | Check eligibility |
- Retrieve data before generating any response
- Reject decisions if data is missing or outdated
Enforce Structured Outputs (Non-Negotiable)
Systems need data objects, not text responses. Instead of text confirmation, return structured data:
| Field | Example |
|---|---|
| Appointment ID | A12345 |
| Patient ID | P678 |
| Slot timestamp | 2026-03-25 10:00 |
| Provider | Dr. Mehta |
| Status | Confirmed |
System requirements:
- JSON-based output
- FHIR mapping (Appointment, Slot)
- Schema validation before write-back
Why this matters:
- Prevents duplicate bookings
- Keeps EHR, billing, and CRM aligned
- Enables denial management automation
Validate Before Going Live
Test decisions against real outcomes before automation.
Shadow Mode Checklist:
- Compare predicted vs actual attendance
- Track decision accuracy
- Monitor override patterns
Go-live only if:
- Calibration is stable
- High-risk predictions are reliable
- Error rates are within limits
Add Engineering Controls
Every system update must pass strict validation checks.
| Control Type | What to Test |
|---|---|
| Feature validation | Data consistency |
| Integration testing | FHIR read/write accuracy |
| Regression testing | Model updates |
| Schema validation | Output correctness |
- Reject invalid outputs automatically
- Log all decisions for audit
Test Under Real Load
Systems must perform under stress, not just ideal conditions.
Simulate:
- High same-day booking volume
- Concurrent updates
- Bulk cancellations
- Peak-hour traffic
Track:
- Failure rate
- Recovery time
- API latency
Include Clinical Review
Adoption depends on trust from frontline teams.
- Validate high-risk scheduling decisions
- Confirm specialty-specific rules
- Review edge cases with schedulers
Feed this input back into:
- Model retraining
- Rule adjustments
What This Means in Practice
Reliable systems follow three rules:
- Ground every decision in real data
- Enforce strict output structure
- Validate continuously before and after deployment
This is what separates a working system from one that fails at scale.
EHR Integration & Interoperability Strategy
If the scheduling system cannot work smoothly with your EHR, it will not survive beyond a pilot, which is why interoperability in healthcare remains a foundational design requirement, not an afterthought.
In most hospitals, the EHR is not just another system. It is the operational backbone. Any AI layer has to plug into it carefully, without creating reconciliation headaches or workflow friction. That means integration decisions need to be practical, not theoretical.
Here is what that looks like in a real enterprise setting:
- FHIR-first approach
Use standard FHIR resources such as Appointment, Slot, Patient, and Practitioner to read availability and update bookings. This reduces custom interface work and makes scaling across departments easier. - Clear resource mapping
Make sure appointment statuses, blocked slots, and provider schedules mean the same thing in both systems. Small mismatches can cause major reporting errors later. - Strong identity resolution
Tie into the Master Patient Index so predictions are attached to the correct patient record across facilities. - Safe transaction controls
Use locking mechanisms and validation checks to prevent duplicate bookings when multiple updates happen at once. - Thoughtful write-back strategy
Many hospitals begin with read-only recommendations, then move to controlled write-back once confidence is built. - Connected operational systems
Keep telephony, CRM, and billing tools in sync so healthcare scheduling automation software does not create new silos.
Integration is not glamorous work, but it determines whether the system is trusted or ignored.
Move from pilot to full deployment with clear integration checkpoints, validation controls, and scalable system design.

Designing Patient and Staff Interaction Layers
Voice and chat interfaces fail in hospitals when they are designed for quiet labs instead of real clinical floors. Understanding how voice technology in healthcare performs in practice is critical before deployment.
In practice, scheduling assistants operate in noisy outpatient clinics, emergency departments, and call centers where staff wear masks, and patients speak with varied accents. Interface design must account for this reality.
Key design considerations:
Handling Real-World Voice Conditions
- Tune speech recognition models for medical terminology, provider names, and specialty vocabulary, capabilities rooted in NLP in healthcare applications.
- Account for mask-induced speech distortion, which can reduce clarity.
- Design for background noise filtering, especially in triage desks and busy clinics.
- Monitor Word Error Rate continuously, not just at launch, a standard metric in speech recognition technology for healthcare environments.
If voice confidence drops below a defined threshold, the system should trigger fallback logic rather than guessing.
Fallback & Escalation Design
When ambiguity occurs:
- Route complex or multi-intent requests to human staff.
- Use structured clarification prompts instead of open-ended repetition.
- Log failure patterns for retraining and refinement.
Emergency escalation rules must be explicit. If language suggests urgency or distress, behavior routing should immediately transfer to a live agent.
Multimodal Strategy
Not every patient prefers voice. Effective AI scheduling assistants offer:
- Voice for low digital literacy populations
- SMS or chat for quick confirmations
- Portal-based booking for authenticated users
Allow seamless switching between channels without losing context.
User-centric interface design is not cosmetic. It directly affects adoption, trust, and operational efficiency.
Compliance, Privacy & Security
If this platform cannot pass a regulatory review, it will not reach enterprise scale.
In hospital systems, scheduling data is tightly connected to patient identity, making healthcare data security a non-negotiable foundation for any AI deployment. That places any AI-driven healthcare workflow automation under formal regulatory oversight. Requirements vary by jurisdiction, so controls must be mapped deliberately.
Below is a region-by-region view of what compliance looks like in practice.
United States
Before deployment in the US, controls must align with federal health privacy law.
| Compliance Area | Enterprise Expectation |
|---|---|
| Legal framework | HIPAA and HITECH |
| Access control | Role-based access integrated with hospital SSO and identity and access management frameworks to meet HIPAA requirements. |
| Encryption | TLS 1.2 or higher in transit, AES-256 at rest with managed key rotation |
| Vendor oversight | Signed Business Associate Agreements with all PHI-handling vendors |
| Incident response | Breach detection and notification aligned with HHS reporting rules |
European Union
In the EU, privacy obligations extend beyond security into lawful processing and patient rights.
| Compliance Area | Enterprise Expectation |
|---|---|
| Legal framework | GDPR |
| Lawful basis | Documented justification for processing appointment and behavioral data |
| Risk assessment | Data Protection Impact Assessment prior to production |
| Data subject rights | Operational workflows for access, correction, and erasure requests |
| Data minimization | Restrict model features to operational necessity |
Australia
Australian deployments require alignment with national privacy principles.
| Compliance Area | Enterprise Expectation |
|---|---|
| Legal framework | Privacy Act 1988 and Australian Privacy Principles |
| Transparency | Clear patient notification regarding scheduling data use |
| Use limitation | Data applied strictly to defined healthcare operations |
| Cross-border transfer | Contractual and technical safeguards for offshore cloud hosting |
Regional Data Residency (Example: UAE, Saudi Arabia)
In several Middle Eastern jurisdictions, data location becomes a primary concern.
| Compliance Area | Enterprise Expectation |
|---|---|
| Hosting requirement | Health data may need to remain within national borders |
| Cross-border controls | Regulatory approval is often required for international transfers |
| Governance alignment | Conformance with national data protection laws and health authority guidance |
Across all regions, consistent enterprise controls should include immutable audit logs, documented model validation and bias testing, version-controlled governance records, and alignment with SOC 2 Type II or ISO 27001 frameworks.
In AI in healthcare operations, compliance architecture determines whether innovation scales or stalls.
Also Read: Blockchain Technology in Healthcare
Appinventiv collaborated with DiabeticU to develop a HIPAA-compliant diabetes management platform focused on secure patient engagement and scalable infrastructure. The engagement required aligning AI-enabled tracking features with healthcare privacy standards while maintaining performance stability. The solution supported real-time health monitoring within a regulated digital health environment.

MLOps & Continuous Monitoring
Without structured MLOps, even a high-performing model will degrade quietly in production.
In real hospital environments, predictive scheduling models interact with shifting patient behavior, seasonal demand, and operational policy changes. Continuous oversight is not optional.
Enterprise monitoring should include:
- Model performance tracking
Monitor AUC, calibration, and precision at operational thresholds across specialties, not just system-wide averages. - Drift detection
Track feature distribution shifts and prediction accuracy decay. For example, changes in booking lead times during flu season can alter model reliability. - Defined retraining cadence
Retrain on rolling 6–12 month windows or trigger retraining when performance drops below predefined thresholds. - Canary deployments
Release updated models to a limited clinic subset before full rollout to validate real-world stability. - Rollback mechanisms
Maintain version-controlled model registries so previous stable versions can be restored immediately. - SLA enforcement
Real-time scheduling APIs should maintain low latency under peak load to protect operational workflows.
Strong scheduling assistant development depends on disciplined lifecycle management, not just initial model accuracy.
Common Implementation Pitfalls and How to Avoid Them
Most AI scheduling projects fail not because the model is weak, but because operational realities are underestimated.
In enterprise hospital environments, problems rarely appear during controlled pilots. They surface three to six months later, when scale, staff behavior, and edge cases collide.

Here are the most common failure points and how to manage them:
Data Quality Collapses After Pilot
Live data streams contain inconsistent cancellation codes, duplicate patient IDs, or missing timestamps that were cleaned during testing. Sudden drop in model calibration accuracy or unexplained utilization variance. Automate data validation checks at ingestion. Monitor feature distribution drift weekly, not quarterly.
Scheduler Workarounds
Staff quietly revert to manual overbooking because they do not trust the system’s recommendations. High override frequency without documented escalation. Track override ratios. Review them in governance meetings. Use overrides as feedback signals, not resistance markers.
Integration Latency in Legacy EHR Environments
Real-time write-back slows during peak hours, causing slot mismatches, a known risk when integrating AI with legacy systems in healthcare environments. API latency spikes above defined SLA thresholds. Stress-test HL7/FHIR adapters under peak simulation before enterprise rollout.
Overbooking Calibration Errors
Probability estimates look accurate overall, but fail in specific specialties. Localized patient dissatisfaction or wait time spikes. Calibrate overbooking thresholds by specialty, not system-wide averages.
Governance Fatigue
Post-launch monitoring weakens. Retraining cadence slips. Model drift was detected but not addressed promptly. Embed monitoring into existing operational dashboards rather than creating parallel reporting channels.
This is where building AI scheduling assistants for healthcare shifts from technical deployment to operational discipline.
Cost Model & Procurement Checklist
For most enterprise hospitals, the total investment for an AI scheduling assistant typically ranges between $50,000 and $500,000 USD, depending on scope, integration depth, and deployment scale.
Smaller specialty pilots sit at the lower end. Multi-site, fully integrated deployments with bidirectional EHR write-back and workforce optimization capabilities trend toward the higher end. The variation is driven more by integration and governance complexity than by the model itself.
Cost Categories
Below are the primary cost drivers in healthcare AI scheduling assistant development:
| Cost Component | What It Covers | Estimated Range (USD) |
|---|---|---|
| Data Engineering |
| $15,000 – $80,000 |
| ML Development |
| $20,000 – $120,000 |
| Cloud Infrastructure |
| $10,000 – $70,000 annually |
| EHR Integration |
| $25,000 – $150,000 |
| Licensing (Voice/SMS) |
| $5,000 – $50,000 annually |
| Change Management |
| $10,000 – $60,000 |
Enterprise-grade healthcare scheduling assistant development often increases in cost when multi-location identity resolution or advanced workforce automation is included.
Procurement Evaluation Checklist
Enterprise procurement should assess vendors or internal build plans against the following:
- Explainability guarantees for audit readiness
- SLA commitments on uptime and inference latency
- Security certifications such as SOC 2 or ISO 27001
- EHR compatibility and proven FHIR integration
- Exit clauses and data portability rights
- Total Cost of Ownership comparison between building internally and buying a managed platform
Cost transparency and governance maturity often separate successful scheduling assistant development from stalled initiatives.
Also Read: Healthcare App Development Cost Guide
Measuring the 35% Operational Efficiency Gain
If the numbers on your operations dashboard do not change, no one will care how advanced the system is.
Around 40% of providers already report measurable efficiency improvements from AI adoption, reinforcing that improving hospital efficiency with AI is achievable when execution is disciplined.
In most hospitals, the real test comes weeks after launch. CFO asks if specialty income improved. Operations looks at utilization reports. Department heads check overtime hours. That is where the 35 percent claim either holds up or falls apart.
Before you turn anything on, freeze a clean baseline. Pull two to three months of data for the same department. Lock in the existing no-show rate, average wait time, slot utilization, and scheduler workload. That becomes your reference point.
Track a focused set of measures:
- No-show rate compared before and after activation
- Slot utilization as a percentage of total available capacity
- Scheduler hours spent on manual coordination
- Revenue recovered from previously unused slots
- Average patient wait time
A practical way to think about it is this:
Operational Efficiency Gain = (no-show improvement + better capacity use + staff time saved)
For example, if a cardiology clinic reduces no-shows from 22 percent to 17 percent, increases slot fill rate by 9 percent, and trims manual scheduling effort by a few hours per week, the combined operational effect becomes meaningful.
Validate results carefully. Compare similar departments or stagger the rollout. Adjust for seasonality. Capacity optimization earns trust only when the improvement is visible, repeatable, and grounded in real operational data.
Change Management & Clinical Adoption
If frontline teams do not trust the system, they will default back to old habits. Effective change management in healthcare starts well before go-live.
In most hospitals, adoption comes down to clarity and comfort. Schedulers want to know what changes. Clinicians want to know it will not disrupt patient care. That conversation has to happen early.
Keep the rollout practical and grounded:
- Stakeholder alignment
Bring operations heads, IT, compliance, and pilot department leaders into the same room. Agree on clear goals and guardrails before activation. - Scheduler-focused training
Use real booking examples. Show how a high-risk appointment is flagged and when an override makes sense. Keep sessions short and repeatable. - Clinical champion involvement
Identify one or two respected physicians to test the system first and share feedback openly. - Escalation governance
Define who reviews flagged issues, how quickly decisions are made, and how adjustments are communicated. - Patient communication
Clearly explain new reminder messages or booking options so patients are not confused by the change.
AI-powered patient flow management works best when it supports staff rather than replacing their judgment, especially when the goal is improving hospital efficiency with AI without disrupting clinical workflows.
Appinventiv partnered with YouCOMM to digitize inpatient communication workflows inside hospital environments. The objective was to reduce response delays and streamline nurse–patient coordination. The team built a structured digital request system that converted bedside needs into trackable, real-time workflows, helping clinical teams prioritize and respond more efficiently within operational constraints.

Build vs Buy: Strategic Decision Framework
The build-versus-buy decision comes down to one question: do you want full control over the engine, or do you want faster deployment with shared responsibility?
For hospital CIOs, this is rarely a purely technical call. It touches procurement timelines, internal data maturity, compliance comfort, and long-term ownership strategy. Some organizations value architectural control. Others prioritize speed and operational lift within the same fiscal year, often evaluating whether to partner with an experienced AI consulting company to accelerate deployment.
Here is a grounded way to think about it:
| Evaluation Factor | Build In-House | Buy Vendor Platform |
|---|---|---|
| Customization depth | Deep tailoring to specialty workflows and local rules | Limited to configuration within the vendor framework |
| Speed to value | Longer ramp-up due to data and integration work | Faster pilot deployment |
| Internal ML maturity | Requires experienced data engineers and MLOps capability | Vendor provides embedded expertise |
| Compliance burden | Full internal accountability | Shared responsibility, often supported by vendor certifications |
| Long-term scalability | Full control over roadmap and cost structure | Dependent on vendor roadmap and pricing |
The right answer depends on your internal capability, urgency, and how central you expect the AI scheduling assistant for healthcare to become within your broader digital strategy.
Compare build and buy options with clear cost, control, and scalability trade-offs before committing.

Future Outlook of AI Scheduling Systems in Healthcare
AI scheduling is moving from reactive optimization to proactive capacity orchestration across entire health systems, a shift central to any Healthcare 4.0 strategy. Three-quarters of leading healthcare organizations are already experimenting with or scaling generative AI in healthcare beyond pilot stages, accelerating this transition.
Today, most deployments focus on no-show prediction and staff allocation. Over the next few years, the scope expands significantly.
Here is where enterprise systems are heading:
Integration with IoMT and Real-Time Signals
Connected medical devices and discharge systems can trigger scheduling events automatically, part of how smart technology in healthcare is reshaping real-time care coordination.
- Post-discharge follow-ups scheduled based on device alerts
- Remote monitoring data influencing appointment urgency
- Real-time bed availability feeds outpatient capacity planning
This tightens the loop between care delivery and scheduling.
Personalized and Context-Aware Scheduling
Future systems will consider a deeper patient context extending the role of personalization in healthcare into scheduling workflows. AI-enabled systems are already embedded in imaging, diagnostics, and clinical decision support, with a growing share of clinical decisions influenced by AI tools, making scheduling the next operational layer to evolve.
- Clinical history influencing specialist routing
- Risk stratification guiding follow-up frequency
- Insurance and authorization validation in real time
Scheduling becomes aligned with clinical pathways, not just availability.
Autonomous Resource Rebalancing
Advanced systems will:
- Reallocate appointment capacity across facilities dynamically, an approach increasingly powered by digital twin technology in complex health networks.
- Shift staffing pools based on forecasted surges
- Optimize specialty distribution across networks
This transforms capacity optimization from local scheduling to network-level orchestration.
Equity and Access Expansion
AI-driven healthcare scheduling solutions can support:
- Load balancing across underserved regions
- Multilingual and voice-first access
- Low-resource hospital automation models
The next evolution of an artificial intelligence scheduling assistant development is not just about efficiency. It is about responsiveness, resilience, and equitable access at scale.
Why Choose Appinventiv for Healthcare AI Scheduling Systems
If you are evaluating partners to build an AI scheduling assistant for healthcare, you are not just buying a model. You are choosing who will carry operational risk with you.
Appinventiv has delivered 500+ digital health platforms and worked with 450+ healthcare clients over 10+ years in HealthTech projects.
That experience shows up in execution. We have integrated 300+ connected medical devices, maintained 99.90% uptime for critical systems, and helped hospitals achieve up to 45% operational efficiency gains in transformation programs.
Clinical data accuracy in deployed systems has crossed 90%+, with patient satisfaction reaching 95% in production apps.
How does Appinventiv build AI scheduling systems for healthcare? Through governance-first AI development services designed specifically for regulated healthcare environments. We design FHIR-based integrations with secure, bidirectional sync. We embed explainability, drift detection, bias audits, and continuous monitoring into every AI scheduling assistant development engagement.
Our model is practical. We start with a discovery workshop, define ROI targets, launch an MVP pilot, and expand in phases aligned with your healthcare AI implementation roadmap.
If you are looking for a partner who understands compliance, scale, and clinical reality, we are ready to build with you.
Frequently Asked Questions
Q. How can AI improve hospital scheduling efficiency?
A. AI improves hospital scheduling efficiency by predicting no-shows, optimizing overbooking decisions, aligning staff rosters with real demand, and automating rescheduling workflows. Instead of reacting to cancellations, hospitals can proactively reallocate capacity and reduce idle slots. Over time, this improves slot utilization, reduces overtime, shortens patient wait times, and supports measurable capacity optimization across departments.
Q. What ROI can hospitals expect from AI scheduling systems?
A. ROI typically comes from reduced no-shows, higher slot utilization, and lower administrative effort. Many hospitals see no-show reductions in the 15 to 25 percent range, utilization increases near 8 to 12 percent, and measurable recovery of previously lost specialty revenue. When combined, these gains can translate into significant operational lift within six to twelve months of deployment.
Q. How do AI scheduling assistants reduce administrative workload?
A. AI scheduling assistants automate confirmation reminders, waitlist management, rescheduling, and real-time availability matching. Instead of manual outbound calls and spreadsheet tracking, schedulers receive prioritized risk flags and system-generated recommendations. This reduces repetitive coordination work, shortens call handling time, and allows administrative teams to focus on exceptions rather than routine appointment management.
Q. What architecture is required for healthcare AI scheduling?
A. A production-ready system requires a FHIR-integrated data layer, a secure API gateway, event-driven messaging, a feature store for consistent model inputs, calibrated prediction models, and a constraint-based optimization engine. It also needs audit logging, drift monitoring, and role-based access control. The architecture must support both read-only pilots and controlled write-back into the EHR.
Q. How does Appinventiv build AI scheduling systems for healthcare?
A. Appinventiv follows a structured healthcare AI implementation roadmap that begins with discovery and data audits, followed by MVP model deployment in controlled pilot settings. We design FHIR-based integrations, embed explainability and monitoring into production workflows, and scale in phases. Our approach emphasizes compliance, governance, and measurable operational outcomes rather than experimental deployments.
Q. Can AI scheduling integrate with EHR systems?
A. Yes, AI scheduling systems integrate with EHR platforms using FHIR APIs and, where necessary, HL7 adapters. Appointment, Slot, Patient, and Practitioner resources are mapped carefully to maintain data consistency. Integration can begin in read-only mode and later move to secure bidirectional write-back with transaction safeguards to prevent double booking or reconciliation errors.
Q. How does user experience design impact AI scheduling assistants in healthcare?
A. User experience directly determines adoption and trust. Effective patient-centric design combines UX and conversational design frameworks with structured conversation flows, multi-turn dialogues, and empathetic logic. Platforms like Rasa enable voice interactions and emergency escalation handling. Design thinking in healthcare, paired with feedback collection, performance metrics, and user-friendly visualization, ensures scheduling assistants remain intuitive and clinically reliable.
Q. Why is defining goals and use cases critical before building an AI scheduling assistant?
A. Clear objectives prevent scope drift and unsafe automation. Hospitals should map stakeholders, define target users, and evaluate challenges using a use case feasibility matrix. Aligning with the WHO Digital Health Intervention classification and FHIR standards ensures interoperability. Goal-based agents, intent detection, fairness metrics, escalation accuracy tracking, hallucination prevention, audit logs, and resource optimization must all tie back to clearly defined outcomes.
Q. Why is stakeholder engagement essential for AI scheduling implementation?
A. Successful deployment depends on early stakeholder analysis, interviews, and alignment around baseline metrics and workflow challenges. Addressing stakeholder resistance requires a phased rollout strategy, clear regulatory obligations, and transparent audit trails. Admin roles with SSO controls, behavior routing, fallback logic, and human-in-the-loop decision pathways ensure accountability while building confidence across clinical and operational teams.
Q. What future trends will shape AI scheduling in healthcare?
A. AI scheduling is evolving toward autonomous decision-making supported by predictive analytics, IoMT devices, and real-time performance tracking. Integration with AI-powered telemedicine, AI-driven genomic analysis, and personalized cancer treatment will influence capacity planning. Continuous monitoring requirements, advanced data encryption, and AI-driven cybersecurity will become critical as systems integrate with disease prediction and prevention tools, and even autonomous surgical assistants.


- In just 2 mins you will get a response
- Your idea is 100% protected by our Non Disclosure Agreement.

Outsourcing product development is not just a buzzword or a futuristic concept; it is a present reality in the modern business world. What started as a trend during the COVID-19 pandemic has become a new norm for businesses across industries. The Grand View Research report indicates that the global business process outsourcing market will hit…

Retail businesses today operate across stores, mobile apps, websites, marketplaces, and fulfillment partners. Each channel generates data, transactions, and customer interactions. When these systems do not work together, growth slows, costs rise, and decision-making becomes reactive. Retail software development has moved far beyond basic POS or eCommerce tools. For many organizations, it now supports pricing,…

When Google acquired Fitbit for $2.1 billion in 2021, it was not just buying a fitness tracker but investing in a thriving ecosystem powered by wearable apps. Fitbit’s success was not just about hardware; its app’s ability to deliver real-time health insights, sync seamlessly with multiple devices, and engage users with personalized recommendations made it…












