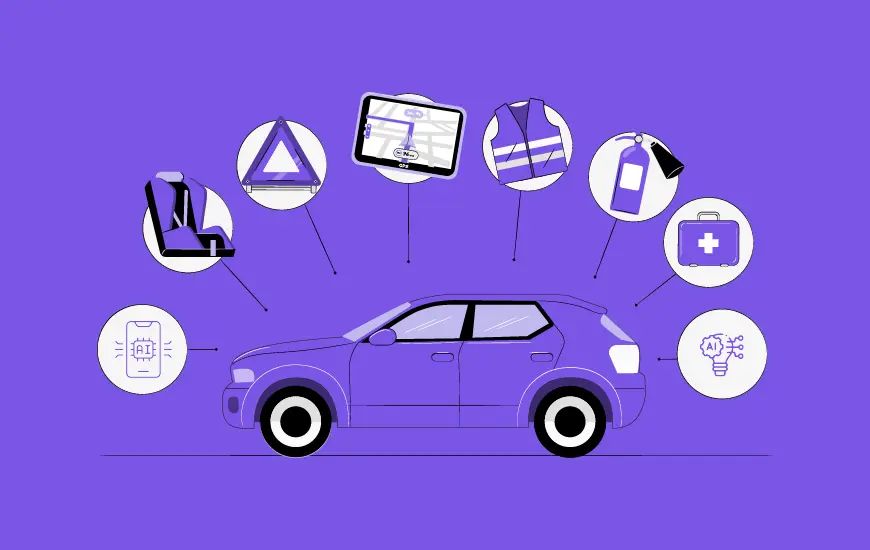
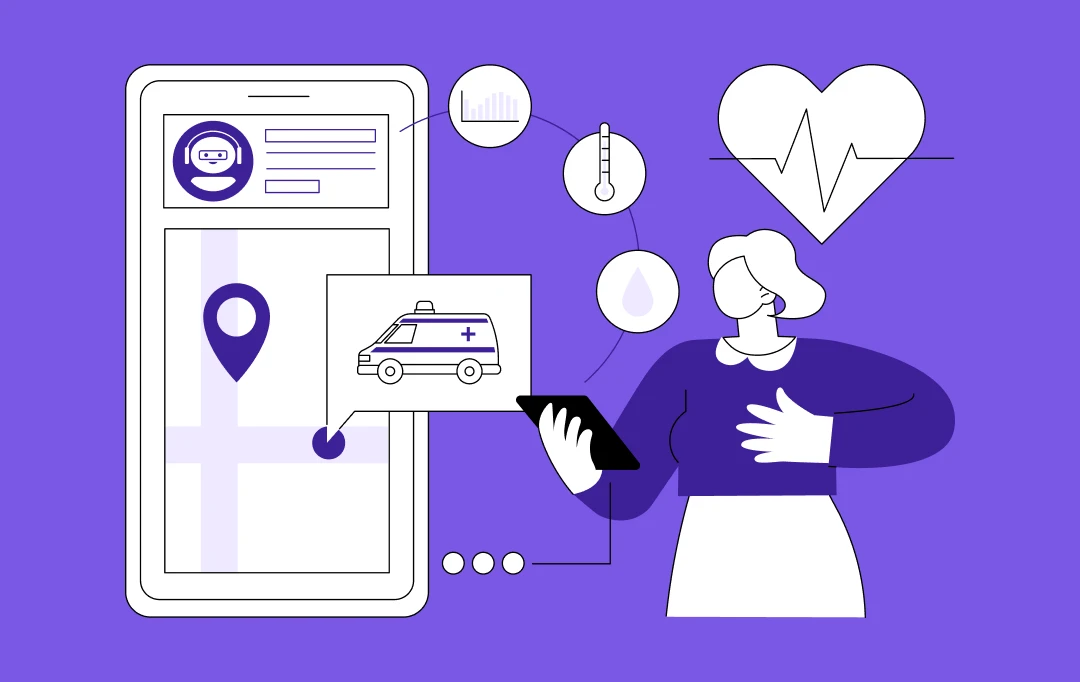
Uncover proof of Appinventiv's impact across 3000+ digital deliveries for 35+ industries. EXPLORE NOW! Uncover proof of Appinventiv's impact across 3000+ digital deliveries for 35+ industries. EXPLORE NOW! Uncover proof of Appinventiv's impact across 3000+ digital deliveries for 35+ industries. EXPLORE NOW! Uncover proof of Appinventiv's impact across 3000+ digital deliveries for 35+ industries. EXPLORE NOW!
- InventivAI
- Featured Insight
 Leader in AI-First Product Engineering Read Full Article
Leader in AI-First Product Engineering Read Full Article
- About
- Services
- Industries
- Portfolio
- Resources RECOMMENDED BlogsView All Blogs
-
 Contact Us
Contact Us