























Spark vs Hadoop: Which Big Data Framework Will Elevate Your Business?

- Advantages of Hadoop Big Data Framework
- Disadvantages of Hadoop Framework
- Benefits of Apache Spark Framework
- Limitations of Spark Big Data Tool
- Spark vs Hadoop: How the Two Big Data Tools Stack Up Against Each Other
- Use Cases of Apache Spark Framework
- Use Cases of Apache Hadoop Framework
- FREQUENTLY ASKED QUESTIONS

“Data is the fuel of Digital Economy”
With modern businesses relying upon heap of data to better understand their consumers and market, the technologies like Big Data are gaining a huge momentum.
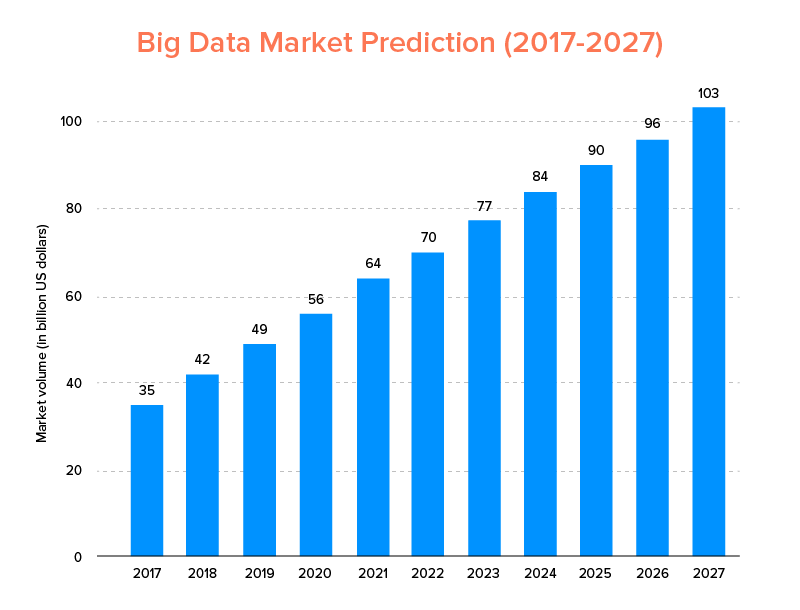
Big Data, just like AI has not just landed into the list of top tech trends for 2020, but is expected to be embraced by both startups and Fortune 500 companies for enjoying exponential business growth and ensure higher customer loyalty. A clear indication of which is that the Big Data market is predicted to hit $103B by 2027.
Now, while this on one side everyone is highly motivated to replace their traditional data analytics tools with Big Data – the one that prepares the ground for advancement of Blockchain and AI, they are also confused about choosing the right Big data tool. They are facing the dilemma of picking between Apache Hadoop and Spark – the two titans of Big Data world.
So, considering this thought, today we will be covering an article on Apache Spark vs Hadoop and help you to determine which one is the right option for your needs.
But, firstly, let’s have a brief introduction of what is Hadoop and Spark.
Apache Hadoop is an open-source, distributed, and Java-based framework that enables users to store and process big data across multiple clusters of computers using simple programming constructs. It comprises of various modules that work together to deliver an enhanced experience, which are:-
- Hadoop Common
- Hadoop Distributed File System (HDFS)
- Hadoop YARN
- Hadoop MapReduce
Whereas, Apache Spark is an open-source distributed cluster-computing big data framework that is ‘easy-to-use’ and offers faster services.
The two big data frameworks are backed by numerous big companies due to the set of opportunities they offer.
Advantages of Hadoop Big Data Framework
1. Fast
One of the features of Hadoop that makes it popular in the big data world is that it is fast.
Its storage method is based on a distributed file system that primarily ‘maps’ data wherever located on a cluster. Also, data and tools used for data processing are usually available on the same server, which makes data processing a hassle-free and faster task.
In fact, it has been found that Hadoop can process terabytes of unstructured data in just a few minutes, while petabytes in hours.
2. Flexible
Hadoop, unlike traditional data processing tools, offers high-end flexibility.
It lets businesses gather data from different sources (like social media, emails, etc.), work with different data types (both structured and unstructured), and get valuable insights to further use for varied purposes (like log processing, market campaign analysis, fraud detection,etc).
3. Scalable
Another advantage of Hadoop is that it is highly scalable. The platform, unlike traditional relational database systems (RDBMS), enables businesses to store and distribute large data sets from hundreds of servers that operate parallely.
4. Cost-Effective
Apache Hadoop, when compared to other big data analytics tools, is much inexpensive. This is because it does not require any specialized machine; it runs on a group of commodity hardware. Also, it is easier to add more nodes in the long run.
Meaning, one case easily increase nodes without suffering from any downtime of pre-planning requirements.
5. High Throughput
In the case of Hadoop framework, data is stored in a distributed manner such that a small job is split into multiple chunks of data in parallel. This makes it easier for businesses to get more jobs done in less time, which eventually results in higher throughput.
6. Resilient to Failure
Last but not least, Hadoop offers high fault-tolerance options which helps to mitigate the consequences of failure. It stores a replica of every block that makes it possible to recover data whenever any node goes down.
Disadvantages of Hadoop Framework
1. Issues with Small Files
The biggest drawback of considering Hadoop for big data analytics is that it lacks the potential to support random reading of small files efficiently and effectively.
The reason behind this is that a small file has comparatively lower memory size that the HDFS block size. In such a scenario, if one stores a vast number of small files, there’s higher chances of overloading of NameNode that stores the namespace of HDFS, which is practically not a good idea.
2. Iterative Processing
The data flow in big data Hadoop framework is in the form of a chain, such that the output of one becomes the input of another stage. Whereas, the data flow in iterative processing is cyclic in nature.
Because of this, Hadoop is an unfit choice for Machine Learning or Iterative processing-based solutions.
3. Low Security
Another disadvantage of going with Hadoop framework is that offers lower security features.
The framework, for example, has security model disabled by default. If someone using this big data tool does not know how to enable it, their data could be at higher risk of being stolen/misused. Also, Hadoop does not provide the functionality of encryption at the storage and network levels, which again increases the chances of data breach threat.
4. Higher Vulnerability
Hadoop framework is written in Java, the most popular yet heavily exploited programming language. This makes it easier for cybercriminals to easily get access to Hadoop-based solutions and misuse the sensitive data.
5. Support for Batch Processing Only
Unlike various other big data frameworks, Hadoop does not process streamed data. It supports batch processing only, and the reason behind is that MapReduce fails to take advantage of memory of the Hadoop Cluster to the maximum.
While this is all about Hadoop, its features and drawbacks, let’s have a look into the pros and cons of Spark to find an ease in understanding the difference between the two.
Benefits of Apache Spark Framework
1. Dynamic in Nature
Since Apache Spark offers around 80 high-level operators, it can be used for processing data dynamically. It can be considered the right big data tool to develop and manage parallel apps.
2. Powerful
Due to its low-latency in-memory data processing capability and availability of various built-in libraries for machine learning and graph analytics algorithms, it can handle various analytics challenges. This makes it a powerful big data option in the market to go with.
3. Advanced Analytics
Another distinctive feature of Spark is that it not only encourages ‘MAP’ and ‘reduce’, but also supports Machine Learning (ML), SQL queries, Graph algorithms, and Streaming data. This makes it suitable for enjoying advanced analytics.
4. Reusability
Unlike Hadoop, Spark code can be reused for batch-processing, run ad-hoc queries on stream state, join stream against historical data, and more.
5. Real-time Stream Processing
Another advantage of going with Apache Spark is that it enables handling and processing of data in real-time.
6. Multilingual Support
Last but not least, this big data analytics tool support multiple languages for coding, including Java, Python, and Scala.
Limitations of Spark Big Data Tool
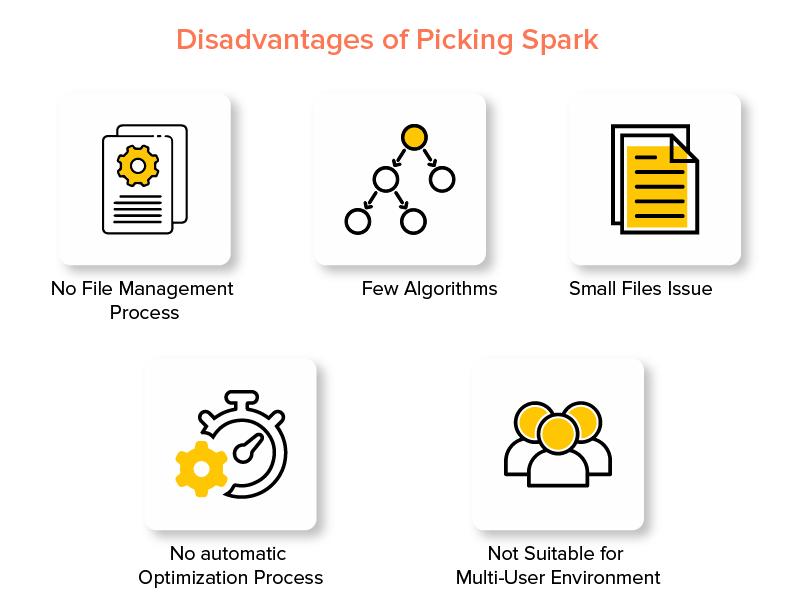
1. No File Management Process
The prime disadvantage of going with Apache Spark is that it does not have its own file management system. It relies on other platforms like Hadoop for meeting this requirement.
2. Few Algorithms
Apache Spark also lags behind other big data frameworks when considering the availability of algorithms like Tanimoto distance.
3. Small Files Issue
Another disadvantage of using Spark is that it does not handle small files efficiently.
This is because it operates with Hadoop Distributed File System (HDFS) which find it easier to manage a limited number of large files over a plenty of small files.
4. No automatic Optimization Process
Unlike various other big data and cloud-based platforms, Spark does not have any automatic code optimization process. One has to optimize code manually only.
5. Not Suitable for Multi-User Environment
Since Apache Spark cannot handle multiple users at the same time, it does not operate efficiently in multi-user environment. Something that again adds to its limitations.
With the basics of both the big data frameworks covered, it is likely that you are hoping to get familiar with the differences between Spark and Hadoop.
So, let’s wait no further and head towards their comparison to see which one leads the ‘Spark vs Hadoop’ battle.
Spark vs Hadoop: How the Two Big Data Tools Stack Up Against Each Other
[table id=38 /]
1. Architecture
When it comes to Spark and Hadoop architecture, the latter leads even when both operate in distributed computing environment.
This is so because, the architecture of Hadoop – unlike Spark- has two prime elements – HDFS (Hadoop Distributed File System) and YARN (Yet Another Resource Negotiator). Here, HDFS handles big data storage across varied nodes, whereas YARN take care of processing tasks via resource allocation and job scheduling mechanisms. These components are then further divided into more components to deliver better solutions with services like Fault tolerance.
2. Ease of Use
Apache Spark enables developers to introduce various user-friendly APIs like that for Scala, Python, R, Java, and Spark SQL in their development environment. Also, it comes loaded with an interactive mode that supports both users and developers. This makes it easy-to-use and with low learning curve.
Whereas, when talking about Hadoop, it offers add-ons to support users, but not an interactive mode. This makes Spark win over Hadoop in this ‘big data’ battle.
3. Fault Tolerance and Security
While both Apache Spark and Hadoop MapReduce offers fault tolerance facility, the latter wins the battle.
This is because one has to start from scratch in case a process crashes in the middle of operation in Spark environment. But, when it comes to Hadoop, they can continue from the point of the crash itself.
4. Performance
When it comes to considering Spark vs MapReduce performance, the former wins over the latter.
Spark framework is able to run 10 times faster on disk and 100 times in-memory. This makes it possible to manage 100 TB of data 3 times faster than Hadoop MapReduce.
5. Data Processing
Another factor to consider during Apache Spark vs Hadoop comparison is data processing.
While Apache Hadoop offers an opportunity to batch processing only, the other big data framework enables working with interactive, iterative, stream, graph, and batch processing. Something that proves that Spark is a better option to go with for enjoying better data processing services.
6. Compatibility
The compatibility of Spark and Hadoop MapReduce is somewhat the same.
While sometimes, both big data frameworks act as standalone applications, they can work together as well. Spark can run efficiently on top of Hadoop YARN, while Hadoop can easily integrate with Sqoop and Flume. Because of this, both support each others’ data sources and file formats.
7. Security
Spark environment is loaded with different security features like event logging and use of javax servlet filters for safeguarding web UIs. Also, it encourages authentication via shared secret and can take leverage of potential of HDFS file permissions, inter-mode encryption, and Kerberos when integrated with YARN and HDFS.
Whereas, Hadoop supports Kerberos authentication, third-party authentication, conventional file permissions, and access control lists, and more, which eventually offers better security results.
So, when considering Spark vs Hadoop comparison in terms of Security, the latter leads.
[Also Read: How to get started with big data analytics in your organization?]
8. Cost-Effectiveness
When comparing Hadoop and Spark, the former needs more memory on disk while the latter requires more RAM. Also, since Spark is quite new in comparison to Apache Hadoop, developers working with Spark are rarer.
This makes working with Spark an expensive affair. Meaning, Hadoop offers cost-effective solutions when one focuses on Hadoop vs Spark cost.
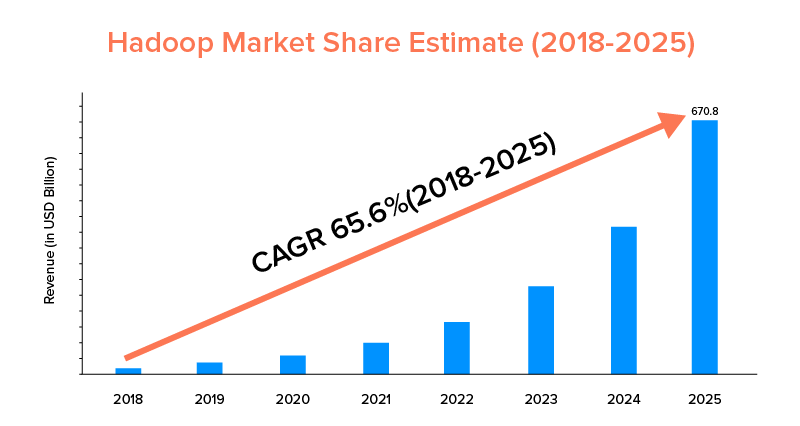
9. Market Scope
While both Apache Spark and Hadoop are backed by big companies and have been used for different purposes, the latter leads in terms of market scope.
As per the market statistics, Apache Hadoop market is predicted to grow with a CAGR of 65.6% during the period of 2018 to 2025, when compared to Spark with a CAGR of 33.9% only.
While these factors will help in determining the right big data tool for your business, it is profitable to get acquainted with their use cases. So, let’s cover here.
Use Cases of Apache Spark Framework
This big data tool is embraced by businesses when they wish to:
- Stream and analyze data in real-time.
- Relish the power of Machine Learning.
- Work with interactive analytics.
- Introduce Fog and Edge Computing to their business model.
Use Cases of Apache Hadoop Framework
Hadoop is preferred by startups and Enterprises when they want to:-
- Analyze archive data.
- Enjoy better financial trading and forecasting options.
- Execute operations comprising of Commodity hardware.
- Consider Linear data processing.
With this, we hope that you have decided which one is the winner of ‘Spark vs Hadoop’ battle with respect to your business. If not, feel free to connect with our Big Data Experts to clear all the doubts and get exemplary services with higher success ratio.
FREQUENTLY ASKED QUESTIONS
1. Which Big Data Framework to Choose?
The choice depends completely on your business needs. If you are focusing on performance, data compatibility, and ease-of-use, Spark is better than Hadoop. Whereas, Hadoop big data framework is better when you focus on architecture, security, and cost-effectiveness.
2. What is Difference between Hadoop and Spark?
There are various differences between Spark and Hadoop. For example:-
- Spark is 100-times factor that Hadoop MapReduce.
- While Hadoop is employed for batch processing, Spark is meant for batch, graph, machine learning, and iterative processing.
- Spark is compact and easier than the Hadoop big data framework.
- Unlike Spark, Hadoop does not support caching of data.
3. Is Spark Better than Hadoop?
Spark is better than Hadoop when your prime focus is on speed and security. However, in other cases, this big data analytics tool lags behind Apache Hadoop.
4. Why Spark is Faster than Hadoop?
Spark is faster than Hadoop because of the lower number of read/write cycle to disk and storing intermediate data in-memory.
5. What is Apache Spark Used for?
Apache Spark is used for data analysis when one wants to-
- Analyze data in real-time.
- Introduce ML, and Fog Computing into your business model.
- Work with Interactive Analytics.

- In just 2 mins you will get a response
- Your idea is 100% protected by our Non Disclosure Agreement.
















